«When the data we feed the machines reflects the history of our own unequal society, we are, in effect, asking the program to learn our own biases».
– Stephen Buranyi
Cos’è e come funziona la Computer Vision
L’enorme potenziale delle tecniche di Machine Learning e di Computer Vision non debbono indurre la società e la politica a demandare ai computer le decisioni su temi ritenuti troppo delicati da affrontare. Studiando sistemi e programmi già sviluppati da ricercatori di diverse parti del mondo, evidenzieremo la falsa imparzialità che l’intelligenza artificiale acquisisce nel momento in cui si sottopongono a essa dei dati che riflettono i nostri stessi bias.
Mubarak Shah, docente alla University of Central Florida e direttore del Center for Research in Computer Vision, nelle sue lezioni ha dato questa definizione di Computer Vision: «Computer Vision is the ability of computers to see». Il computer quindi analizza un’immagine o un video (che altro non è che una serie di immagini in sequenza) e ne studia le caratteristiche principali, traendo da esse le informazioni volute dallo sviluppatore del programma.
Prendiamo quindi le basi su cui poggia l’analisi di un’immagine. Un’immagine è caratterizzata dalla sua risoluzione, dalla luminosità e dal colore dei pixel che la compongono. Quest’ultimo è determinato da una terna di numeri, ognuno dei quali compreso tra 0 e 255, che definiscono la quantità rispettivamente di rosso, verde e blu. Ad esempio, un pixel di un blu molto intenso sarà associato a una terna di numeri del tipo (R, G, B) = (40, 40, 220), mentre uno di colore violaceo sarà qualcosa come (R, G, B) = (180, 30, 180).
Consideriamo un caso semplice, in cui, fissato un frame di un video, si vuole far trovare al computer qual è il pixel più blu in quell’istante e confrontarlo con quello agli istanti successivi. Per esempio, una situazione del genere può presentarsi se vogliamo che il computer focalizzi la sua attenzione su un oggetto di un certo colore (il blu, in questo caso) e ne segua i movimenti.
Il primo passo è quindi introdurre una nozione di “distanza” dal colore blu, così da poter dire se un certo colore sia più vicino al blu rispetto a un altro. Matematicamente, c’è un modo molto naive di rispondere a questa esigenza: poiché ad ogni colore è associata una terna di numeri (r, g, b), la distanza tra due colori è data dalla cosiddetta “distanza euclidea”:
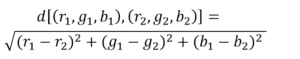
Così, possiamo fissare il colore blu (0,0,255) e determinare la distanza di tutti gli altri pixel da esso. Per ogni pixel calcoliamo questa distanza, troviamo quello che la rende minima e chiediamo al pc di memorizzare quel pixel. Possiamo programmare il pc in modo che evidenzi quel pixel con un quadratino, per esempio; rieseguiamo l’operazione con i frame successivi, determinando di volta in volta qual è il pixel più vicino al blu ed evidenziandolo con lo stesso quadratino di prima. Ecco che riusciamo a tener traccia dell’oggetto blu, come volevamo.
Questa è solo un’idea semplice, basata sull’analisi di uno dei parametri che definiscono l’immagine e il confronto tra i vari frame. Si può chiedere, come fatto in questo video, che il computer determini quale sia l’oggetto più vicino allo schermo, oppure cosa si stia muovendo e cosa invece non cambi. Ci sono intere librerie di Computer Vision per Java, con i codici di programmi dalle funzionalità più varie.
Computer Vision e Machine Learning
Nel paragrafo precedente abbiamo visto come un computer possa studiare in modo semplice un’immagine. Proseguiamo ora mostrando come quest’analisi di base viene adottata per far sì che un computer impari a classificare ciò che gli viene mostrato. Supponiamo di sottoporre al sistema quest’immagine di un’arancia.

Ora, lo studio può essere basato su diversi parametri: pensiamo principalmente alla forma e al colore. Potremmo fissare come al paragrafo precedente il colore arancio e vedere quali sono i pixel con la minima distanza da esso; chiaramente ci sono diverse sfumature di arancio presenti nell’immagine, quindi fissare un colore di riferimento non è l’operazione migliore. Si ricorre allora a una funzione di molti editor di immagini, come GIMP e Photoshop, nota come Eye Dropper, che permette di analizzare i vari colori presenti nell’immagine; questi stessi editor hanno poi altri strumenti tramite cui effettuare questo tipo di analisi su arbitrarie regioni dell’immagine, non solo su singoli pixel. In questo modo, il rilevamento diviene più accurato man mano che si scandagliano le varie regioni nell’immagine. Chiediamo poi al computer di riprodurre su schermo quel che ha “visto”, cioè i risultati della sua indagine su forma e colore dell’oggetto esaminato, e confrontiamo il suo feedback con l’immagine originaria; se questi ultimi due sono sufficientemente simili, allora potremo dirci soddisfatti, altrimenti sottoponiamo al sistema un’altra immagine di un’arancia, e chiediamo di ripetere lo stesso studio, tutto finché non saremo soddisfatti del feedback che ci propone.
A quel punto, il computer avrà un’idea di cosa gli chiediamo quando vogliamo un’arancia, grazie a un database di esempi che gli abbiamo fornito insieme al nostro livello di soddisfacimento in merito ai risultati che aveva prodotto; il passaggio successivo sarà allora dargli un’immagine di arancia che lui non aveva ancora mai analizzato, e chiedergli di produrci un feedback a partire da quella. Questo è esattamente ciò di cui si occupa il Machine Learning: secondo la definizione di Wikipedia, «Machine learning is a field of computer science that gives computers the ability to learn without being explicitly programmed».
Fondamentalmente, l’idea è di usare i dati prodotti nell’analisi del dataset per dare al computer una regola con cui potrà discernere e categorizzare le immagini che analizzerà in seguito. Nel caso dell’arancia, si realizza un grafico 3D dove rappresentare i colori di ogni pixel che compone l’immagine, in cui l’asse x corrisponde al valore del colore rosso, l’asse y a quello del verde e l’asse z a quello del blu. Nel caso dell’arancia in Figura 2, nel grafico troveremo due nuvole di punti: una intorno ai valori di rosso, verde e blu corrispondenti all’arancia, e una intorno ai valori corrispondenti allo sfondo bianco. Diremo allora al sistema che, ogni volta che analizzerà un’immagine, dovrà classificare come “arancia” ciò che si trova all’interno di una regione corrispondente circa alla prima delle due nuvole sopra descritte.

Come sarà ovvio immaginare, un’identificazione basata solo sul colore degli oggetti non è molto efficace. Per aiutare il sistema a classificare correttamente cos’è un’arancia e cosa non lo è, gli suggeriremo allora che le arance hanno una forma tondeggiante: con lo stesso procedimento di trial and error descritto prima per il colore, chiederemo al programma di estrarre dal dataset a sua disposizione la forma delle arance, e valuteremo di volta in volta il feedback che ci dà, fino a ritenerci soddisfatti.
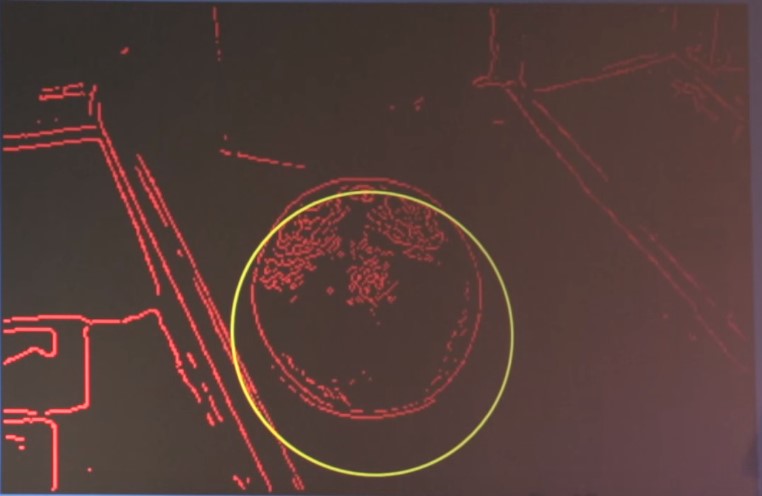
Queste sono un po’ le idee di base con cui si insegna al sistema come classificare gli oggetti. Chiaramente, quello dell’arancia è un caso piuttosto semplice, sia per la forma sia per i colori, ma le tecniche di Machine Learning e la quantità di immagini e video disponibili oggi permettono ai computer di imparare abbastanza agevolmente a categorizzare anche immagini più complesse. Difatti, sono stati sviluppati sistemi di videomonitoraggio in aeroporti, strade e marciapiedi, tramite cui è possibile riconoscere e tracciare le traiettorie di persone e auto, di capire se le persone stanno correndo, camminando, inseguendosi e se sia in corso una colluttazione o meno: un video dimostrativo, di appena un minuto, di un software in grado di distinguere queste situazioni si può trovare qui. Presentazioni più approfondite sulle capacità dei software in tale ambito possono essere trovate qui. Il loro impiego nella nostra vita quotidiana è stato esteso perfino al punto da renderli in grado di monitorare il lavoro svolto dai dipendenti di un’azienda, come nel caso del software NUAProcess: «NUAProcess is a software product to automatically monitor and give support to processes performed by workers in their working place. The system uses innovative artificial vision and augmented reality technologies to guide the worker through assembling processes. It monitors their working flow and checks for errors». Per non parlare della possibilità di usare l’enorme potere delle reti neurali per il nobile scopo di riconoscere e classificare bradipi.
Diamo quindi per assodato il fatto che i computer siano in grado di imparare da noi, una volta che gli forniamo un numero sufficiente di esempi da studiare. Diventa allora fondamentale concentrarsi proprio su quali informazioni stiamo passando all’Intelligenza Artificiale; come nella pedagogia, difatti, sappiamo che i bambini imparano presto ciò che noi gli insegniamo e assorbono sostanzialmente qualunque informazione gli viene trasmessa, per cui ci deve essere un grosso atto di responsabilità da parte nostra.
Garbage in, garbage out
In Computer Science è diffuso questo modo di dire: garbage in, garbage out. Quando diamo ai computer dati che riflettono i nostri pregiudizi, loro li assorbono e li imitano, dando vita a sistemi che hanno quegli stessi pregiudizi – da chatbot anti-semitiche a software razzisti.
Questo è il curioso caso di Tay, un software che era stato programmato per inserirsi su Twitter, avviare conversazioni con utenti reali e permettere ai ricercatori di verificare le capacità di comprensione del bot stesso, nonché i suoi progressivi miglioramenti nel rapportarsi all’utente reale. Purtroppo, finì che Tay rimase bloccato in un loop che lo portò a citare Hitler, supportare Trump, sostenere che l’11 settembre sia stato un complotto e altre amenità.
Prendiamo ad esempio il caso denunciato dall’organizzazione non-profit newyorkese ProPublica. In diverse zone degli USA sono attivi degli algoritmi, adoperati dal software COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) elaborato dall’azienda Northpointe, che valutano i cosiddetti risk assessments, ovvero dei punteggi che i computer assegnano a una persona (solitamente, un indagato o un detenuto) in base al rischio che questa possa commettere reati; questi punteggi poi influiscono sulla decisione dei giudici in merito all’importo di un’eventuale cauzione per il rilascio del detenuto, così come su quanto sicuro sia rimettere quest’ultimo in libertà.
ProPublica ha allora considerato 7000 individui che erano stati arrestati in una contea della Florida, insieme ai loro valori di risk assessments assegnati da COMPAS, e ha controllato quanti, fra quelli giudicati «ad alto rischio di commettere nuovamente un reato nei successivi due anni», siano stati effettivamente imputati di nuovi crimini nei due anni successivi. Le previsioni sono risultate incredibilmente inaffidabili: solo il 20% degli individui giudicati pericolosi effettivamente ha poi commesso reati di una certa rilevanza nel periodo di tempo esaminato; la percentuale sale al 61% (poco più di quanto si possa fare lanciando una moneta!) solo se si considerano infrazioni “minori”, come guidare con la patente scaduta. Non è neanche la prima volta che viene contestato l’uso di strumenti volti a stabilire i risk assessments, per «l’indubbio aggravamento della già intollerabile disparità razziale nel nostro sistema giudiziario».
Fin qui diremmo semplicemente che l’algoritmo non funziona; c’è tuttavia dell’altro che è emerso da questa analisi. COMPAS non solo non funziona, ma ha anche pregiudizi razziali:
- L’errore nella valutazione è stato commesso su imputati neri quasi il doppio delle volte rispetto ai bianchi.
- Gli imputati bianchi sono stati giudicati erroneamente “a basso rischio” più spesso dei neri.
E non sono errori dovuti alla storia passata degli imputati, alla loro età o a un qualsiasi altro fattore personale al di fuori del colore della pelle. Come mostrato in questo articolo di Jeff Larson, l’analisi è stata ripetuta tenendo conto solamente del colore della pelle degli imputati. Ne è risultato che l’errore nel definire ad alto rischio di reiterazione di una qualsiasi infrazione per un imputato è stato commesso il 77% delle volte sui neri e il 45% sui bianchi. Si è dunque nella situazione per cui il sistema giudiziario americano, accusato di essere razzista, ha chiesto aiuto alla tecnologia, solo per poi scoprire che anche gli algoritmi avevano questo tipo di bias. E, mentre i computer imparano e si adattano, diventano sempre meno chiari e difficili da capire i meccanismi con cui le loro complesse interazioni di algoritmi abbiano generato un certo risultato problematico. E, anche se fossimo in grado, le aziende non sono generalmente ben disposte a divulgare il funzionamento interno dei loro algoritmi (ed è proprio quanto ha dichiarato la Northpointe stessa, nonostante si sia preoccupata di affermare che i risultati evidenziati da Propublica siano errati).
Quello di COMPAS non è affatto un caso unico. Al giorno d’oggi vengono adottati sistemi di Computer Vision nell’intera attività di predictive policing, tramite la quale si cerca di stabilire quali siano le aree in una regione (o i quartieri in una città) maggiormente insicure e più esposte a furti, omicidi e reati in genere: si veda ad esempio il caso del software HunchLab in questo articolo. Come ha commentato Kade Crockford, il direttore del programma Technology for Liberty dell’American Civil Liberties Union del Massachusetts: «Predictive policing is based on data from a society that has not reckoned with its past, adding a veneer of technological authority to policing practices that still disproportionately target young black men». Ma con le tecniche di Computer Vision e di analisi dei volti si è andati anche oltre.
A novembre dello scorso anno due ricercatori, Xiaolin Wu e Xi Zhang, hanno pubblicato uno studio dal titolo Automated Inference on Criminality Using Face Images, che già fa pensare a qualche teoria lombrosiana: difatti, nella prima versione dell’articolo (che è stato poi rivisto e modificato due volte nei mesi successivi, fino a marzo 2017, a seguito della bufera che questo studio ha comprensibilmente provocato), i ricercatori affermano che i computer, tramite tecniche di Machine learning, hanno analizzato i volti di persone vissute nel 1856, distinti per età, sesso, razza ed espressione facciale, di cui metà erano detenuti. L’obiettivo era determinare se ci fossero delle caratteristiche che permettessero alle macchine di individuare con successo quali fossero criminali e quali no, solo analizzando il volto di queste persone. Al termine di questo studio, i ricercatori sostengono di essere riusciti a determinare tali caratteristiche. In particolare, sostengono di aver determinato parametri nel viso tramite cui predire con successo se un altro individuo sia un potenziale criminale o meno: la curvatura delle labbra, la distanza dell’occhio dalle sopracciglia, l’angolo naso-bocca.
Questa conclusione ha talmente del paradossale da sottolineare nuovamente un fatto: i computer assimilano ciò che gli viene trasmesso, rispecchiando i bias e gli intenti di chi li programma, insieme ai vizi e ai pregiudizi della società. Immaginiamo di dover distinguere quali impiegati di un’azienda hanno potenziali capacità manageriali e quali no. Se usassimo gli stessi programmi di Computer Vision e Machine Learning su un dataset di immagini di attuali CEO di aziende importanti, cosa ne verrebbe fuori? Facile: il computer osserverebbe subito che, di tutti i personaggi a capo di aziende importanti, pochissime sono le donne. Ne dedurrebbe allora che le donne non sono portate per una posizione di leader, e come tali le segnalerà quando il responsabile delle risorse umane in azienda dovrà valutare eventuali promozioni. Come ha affermato in merito lo scrittore londinese Stephen Buranyi, «When the data we feed the machines reflects the history of our own unequal society, we are, in effect, asking the program to learn our own biases».
I computer non diventano razzisti o sessisti da soli; imparano da noi a esserlo. L’Intelligenza Artificiale ha i nostri occhi, amplifica disuguaglianze e stigmatizzazioni già presenti nella nostra società, ed è un serio pericolo attribuirle un’aura di imparzialità nel prendere decisioni di cui noi non vogliamo assumerci la responsabilità.